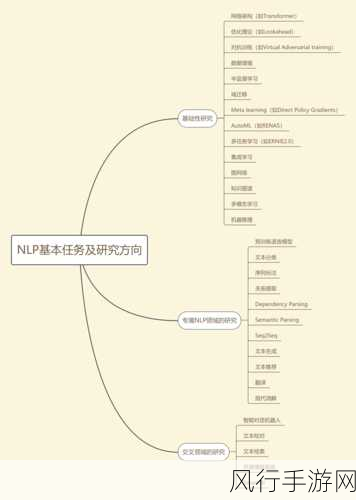
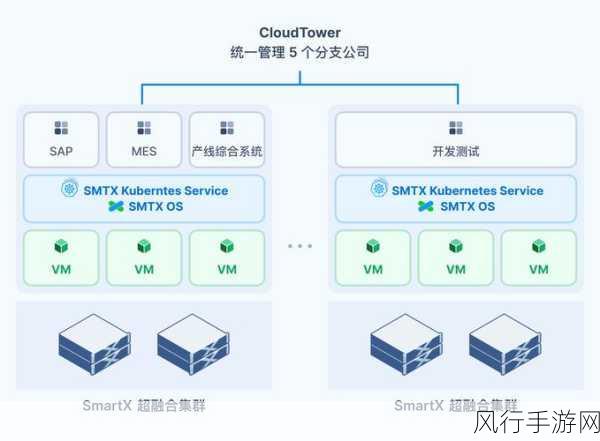
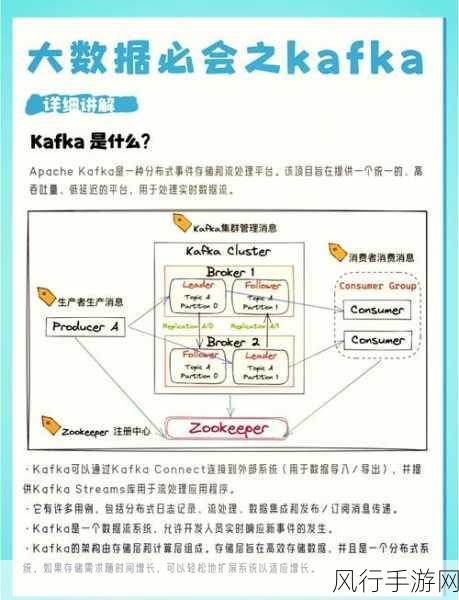
Kafka 作为一款高性能的分布式消息系统,在数据传输和存储过程中,序列化起着至关重要的作用,序列化是将数据结构或对象转换为字节序列的过程,以便在网络中传输或存储到磁盘,Kafka 支持多种序列化方式,每种方式都有其特点和适用场景。
常见的 Kafka 序列化方式包括 Java 原生序列化、JSON 序列化、Avro 序列化和 Protobuf 序列化等。
Java 原生序列化是 Java 语言自带的序列化机制,它使用方便,无需引入额外的库,但存在一些明显的缺点,其序列化后的字节数组通常较大,导致网络传输和存储开销增加,Java 原生序列化的版本兼容性较差,如果对象的结构发生变化,可能导致反序列化失败。
JSON 序列化是一种广泛使用的文本格式序列化方式,它具有良好的可读性和跨语言支持性,JSON 格式的数据易于理解和处理,对于开发和调试非常友好,JSON 序列化的性能相对较低,特别是在处理大量数据时,其序列化和反序列化的速度较慢。
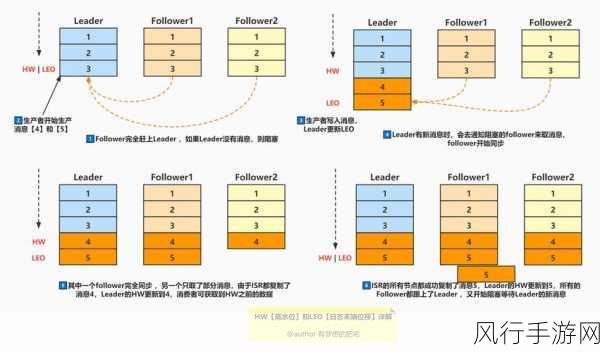
Avro 序列化是一种高效、紧凑的二进制序列化格式,Avro 定义了数据的模式(Schema),在序列化和反序列化时,根据模式进行处理,这使得 Avro 能够在保证数据准确性的同时,实现高效的压缩和快速的处理,Avro 还支持模式演化,即在不破坏兼容性的前提下,对数据的结构进行修改。
Protobuf 序列化也是一种高效的二进制序列化方式,它同样需要定义数据的结构,但与 Avro 相比,Protobuf 在某些场景下可能具有更好的性能,Protobuf 生成的序列化代码简洁高效,并且在网络传输和存储方面具有出色的表现。
在选择 Kafka 序列化方式时,需要综合考虑多方面的因素,比如数据的大小、性能要求、跨语言支持需求以及模式的变更频率等,如果对性能要求极高,并且数据结构相对稳定,Avro 或 Protobuf 可能是更好的选择,如果需要良好的可读性和跨语言支持,JSON 可能更合适,而 Java 原生序列化则在一些简单的场景或者对性能要求不高的情况下可以使用。
了解和掌握 Kafka 的各种序列化方式,能够帮助我们在实际应用中根据具体需求做出最佳选择,从而构建出高效、可靠的消息处理系统。