Schema 数据库在当今的数据处理领域中扮演着重要的角色,一个关键的问题是,它是否能够有效地支持复杂查询呢?
要回答这个问题,我们首先需要了解什么是复杂查询,复杂查询通常涉及多个表的关联、复杂的条件判断、聚合函数的运用以及数据的分组和排序等操作,这些操作的组合使得查询的逻辑变得复杂,对数据库的性能和功能提出了更高的要求。
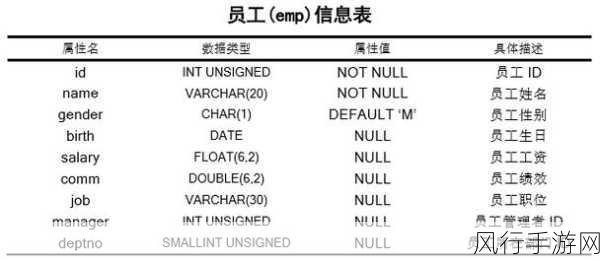
Schema 数据库在处理复杂查询方面具有一定的优势,其良好的数据结构设计和索引机制能够提高查询的效率,通过合理地创建索引,可以加快数据的检索速度,减少查询的响应时间。
但同时,Schema 数据库也面临着一些挑战,当数据量巨大且查询逻辑极其复杂时,可能会出现性能瓶颈,过多的表关联可能导致查询计划的优化变得困难,从而影响查询的执行效率。
Schema 数据库对于一些特殊的查询需求,可能需要额外的配置和优化,对于分布式数据库环境下的复杂查询,需要考虑数据的分布策略和网络延迟等因素。
为了充分发挥 Schema 数据库在复杂查询中的性能,开发者和管理员需要采取一系列的措施,他们需要精心设计数据库结构,确保表之间的关系合理,避免过度冗余的数据,要根据业务需求合理创建索引,并且定期对数据库进行性能监测和优化。
Schema 数据库在一定程度上能够支持复杂查询,但需要在数据库设计、优化和管理等方面下功夫,以确保其能够满足实际业务中复杂查询的需求,为用户提供高效、准确的数据服务。