在当今数字化时代,数据的规模和复杂性不断增长,如何有效地管理和组织数据成为了至关重要的问题,对于使用 MongoDB 进行数据存储和处理的开发者来说,掌握数据建模中的数据分区技巧是提升系统性能和可扩展性的关键之一。
数据分区,就是将大规模的数据按照一定的规则和策略划分到不同的存储区域或节点中,以实现更高效的数据访问和处理,在 MongoDB 中,实现数据分区并非一蹴而就,需要综合考虑多个因素,包括数据的特点、访问模式、业务需求等。
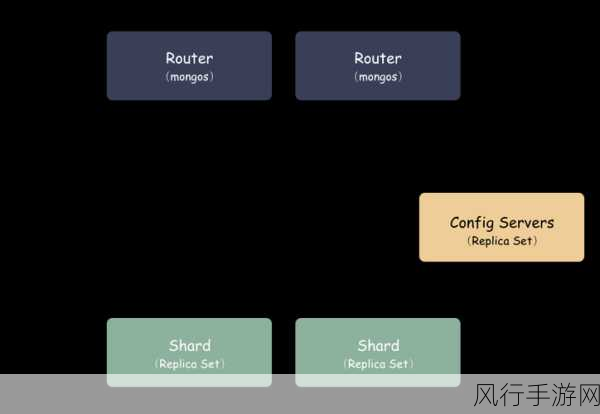
要实现 MongoDB 数据分区,我们需要先明确分区的目标和原则,分区的目的是为了减少数据的竞争和冲突,提高并发处理能力,以及便于数据的分布和扩展,原则上,应尽量保证分区的均衡性,避免某些分区过大或过小,从而影响整体性能。
一种常见的 MongoDB 数据分区方式是基于范围的分区,按照某个字段的值范围将数据划分到不同的分区中,假设我们有一个电商平台的订单数据库,我们可以按照订单金额的范围进行分区,将金额较小的订单划分到一个分区,金额较大的订单划分到另一个分区,这样,在查询特定金额范围内的订单时,可以直接定位到对应的分区进行处理,提高查询效率。

另一种方式是基于哈希的分区,通过对某个字段进行哈希计算,将数据均匀地分布到不同的分区中,这种方式适用于数据分布较为随机,没有明显范围特征的情况。
在实际应用中,还需要考虑分区的维护和管理,当数据量增长或业务需求发生变化时,可能需要对分区进行调整和重新划分,这就要求我们在设计之初就考虑到分区的灵活性和可扩展性。
数据分区也并非适用于所有场景,对于数据量较小、访问模式简单的应用,过度的数据分区可能会带来额外的复杂性和管理成本,在决定是否进行数据分区以及选择何种分区方式时,需要进行充分的性能测试和评估。
MongoDB 数据建模中的数据分区是一项复杂而重要的任务,需要我们深入理解业务需求,结合数据特点和系统架构,选择合适的分区策略,并不断优化和调整,以实现高效的数据管理和处理,为业务的发展提供有力的支持。