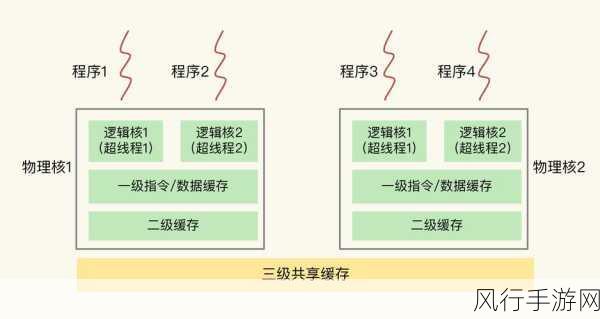
在当今数字化信息飞速发展的时代,网络数据的获取变得愈发重要,而 Python 爬虫作为一种高效的数据采集工具,在帮助我们获取所需信息的过程中发挥着关键作用,验证码的出现却给爬虫带来了不小的挑战。
验证码的存在旨在防止自动化程序的恶意访问和数据采集,它是一种有效的防护机制,但对于爬虫开发者来说,如何处理验证码就成为了一个必须要解决的问题。

处理验证码的方法多种多样,其中一种常见的思路是通过图像识别技术来破解验证码,这需要运用到计算机视觉和机器学习的知识,需要对验证码图像进行预处理,包括去噪、二值化等操作,以提高图像的质量和清晰度,使用深度学习模型,如卷积神经网络(CNN),对验证码进行训练和识别,但这种方法的实现难度较大,需要大量的标注数据和强大的计算资源。
另一种较为简单的方法是利用第三方验证码识别服务,市面上有一些专门提供验证码识别服务的平台,它们通常具有较高的识别准确率,但使用这种服务需要支付一定的费用,并且可能存在法律和道德上的风险。
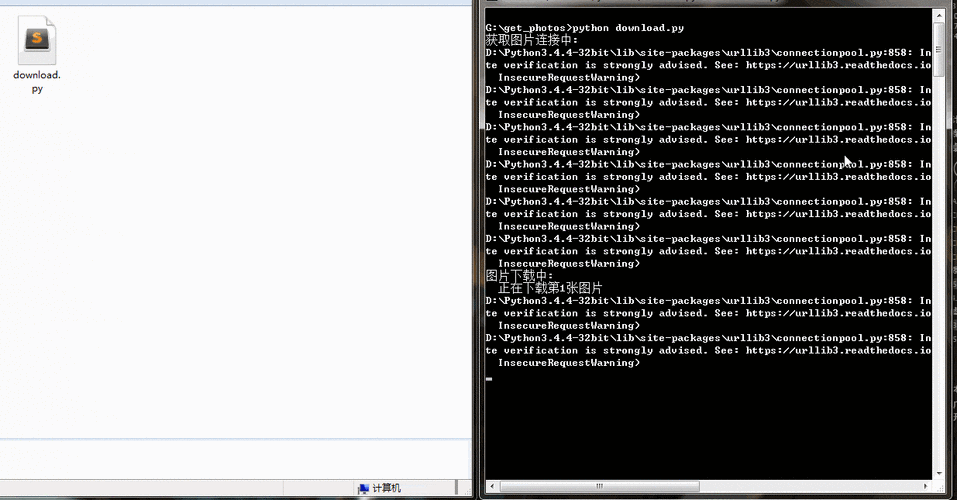
还有一种策略是模拟人工操作来绕过验证码,通过设置合理的请求间隔和频率,尽量减少被服务器识别为爬虫的可能性,或者尝试从网页的其他部分获取所需信息,而不是直接面对验证码的阻碍。
处理 Python 爬虫匹配中的验证码并非易事,需要综合考虑多种因素,并根据具体情况选择合适的方法,在进行爬虫开发时,必须遵守法律法规和道德规范,确保数据采集的合法性和正当性,只有在合法合规的前提下,才能充分发挥 Python 爬虫的优势,为我们的工作和研究提供有价值的数据支持。