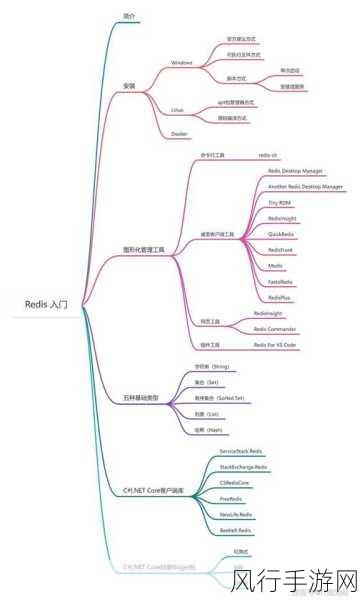
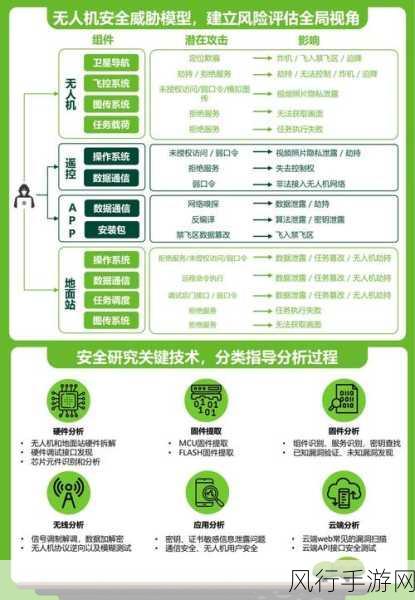
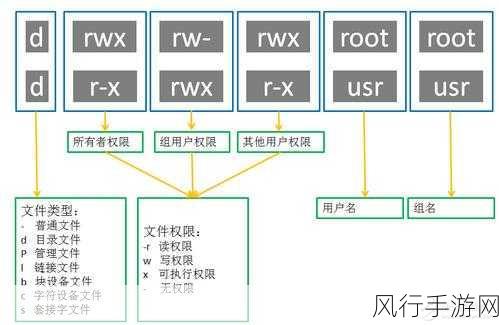
HBase 作为一种分布式的、面向列的开源数据库,其存储结构中的数据缓存机制对于提升系统性能和数据访问效率起着至关重要的作用。
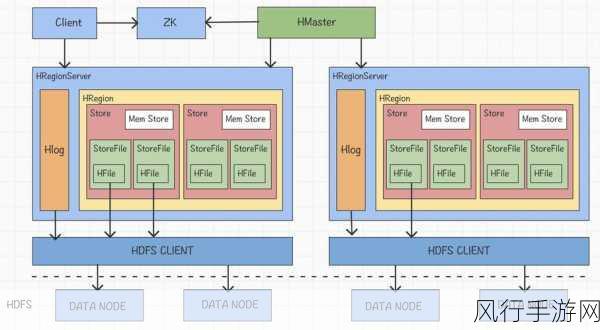
HBase 的存储结构具有独特的设计,为数据缓存提供了良好的基础,它基于 Hadoop 的分布式文件系统 HDFS 进行数据存储,并采用了 Region 作为数据管理的基本单元,每个 Region 包含了一定范围内的数据行,这些数据行按照行键进行排序和存储。
在数据缓存方面,HBase 采用了多种策略来优化数据的访问,MemStore 是一个重要的缓存组件,当数据被写入 HBase 时,首先会被写入 MemStore 中进行缓存,MemStore 本质上是一个内存中的数据结构,它能够快速地接收和处理写入的数据,并在达到一定条件时将数据刷写到磁盘上的 StoreFile 中,这种先缓存后写入磁盘的方式,大大提高了数据写入的性能,减少了磁盘 I/O 操作的次数。
HBase 还使用了 BlockCache 来缓存从磁盘读取的数据块,当客户端请求读取数据时,HBase 会首先在 BlockCache 中查找是否存在所需的数据块,如果存在,直接从缓存中获取数据,避免了再次从磁盘读取,从而加快了数据读取的速度。
HBase 的数据缓存机制还能够根据数据的访问频率和热度进行动态调整,对于经常被访问的数据,会在缓存中保留更长的时间,以提高后续访问的效率,而对于不常访问的数据,则会逐渐从缓存中淘汰,为新的热点数据腾出空间。
为了有效地利用数据缓存,合理配置 HBase 的相关参数也是非常重要的,调整 MemStore 的大小、BlockCache 的容量以及缓存策略的相关参数等,可以根据实际的业务需求和系统负载来优化缓存的性能。
深入理解 HBase 的存储结构以及其数据缓存机制,对于充分发挥 HBase 的性能优势,满足各种复杂的业务场景需求具有重要意义,通过不断优化和调整缓存相关的配置参数,能够使 HBase 在处理大规模数据时表现得更加出色,为企业和用户提供高效、稳定的数据存储和访问服务。