Hadoop 作为大数据领域的重要技术框架,其核心组件在不同规模的应用场景中发挥着关键作用,但究竟 Hadoop 的核心组件适合怎样的规模呢?这是一个值得深入探讨的问题。
Hadoop 由多个关键组件构成,包括 HDFS(Hadoop 分布式文件系统)、MapReduce(分布式计算模型)、YARN(资源管理框架)等,这些组件协同工作,为处理大规模数据提供了强大的支持。
在小规模的数据处理场景中,Hadoop 的核心组件可能并非是最优选择,小规模数据量通常可以通过传统的数据库管理系统或者单机处理工具来完成,因为部署和维护 Hadoop 集群需要一定的资源和技术投入,当数据规模逐渐增大,达到一定的量级,TB 级甚至 PB 级时,Hadoop 的优势就开始显现出来。
HDFS 作为 Hadoop 的分布式文件存储系统,能够在大规模集群中可靠地存储海量数据,它通过数据块的分布式存储和副本机制,确保了数据的高可用性和容错性,对于大规模的数据存储需求,HDFS 可以轻松应对,无论是存储海量的日志文件、图像数据还是其他类型的大规模数据。
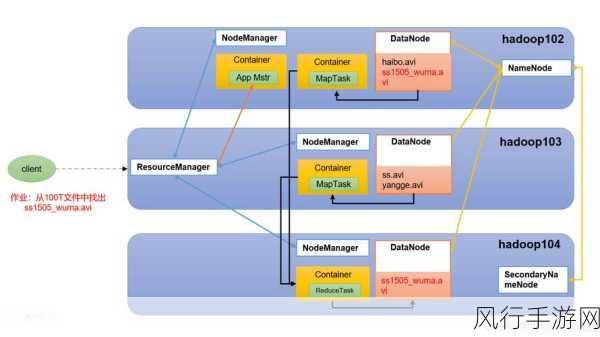
MapReduce 作为 Hadoop 的计算模型,适用于处理大规模的并行计算任务,在处理海量数据的数据分析、数据挖掘等任务时,MapReduce 能够将复杂的计算任务分解为多个小的子任务,并在集群中的多个节点上并行执行,从而大大提高计算效率。
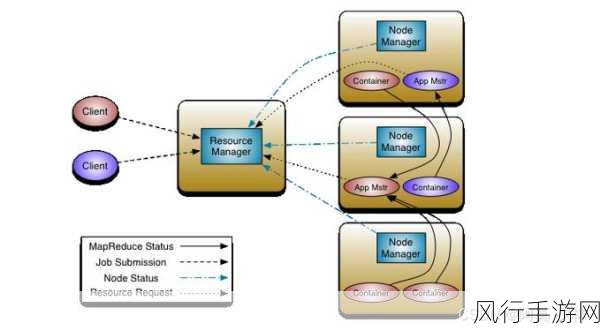
YARN 则为 Hadoop 集群提供了资源管理和调度的功能,在大规模集群中,有效地管理和分配计算资源对于提高系统的整体性能至关重要,YARN 能够根据不同的应用需求,合理地分配 CPU、内存等资源,确保各个任务能够高效地执行。
但需要注意的是,虽然 Hadoop 的核心组件在处理大规模数据时表现出色,但在实际应用中,还需要根据具体的业务需求、数据特点以及技术团队的能力来综合考虑是否选择 Hadoop 以及如何优化配置其核心组件。
Hadoop 的核心组件在大规模数据处理场景中具有显著的优势,但对于不同规模的应用,需要进行全面的评估和权衡,以选择最适合的技术方案来满足业务需求。