Flink 作为一种强大的流处理框架,与 Kafka 进行连接已成为许多大数据处理场景中的常见组合,这种连接究竟会对系统产生怎样的影响呢?
Kafka 以其高吞吐量、可扩展性和分布式特性而闻名,能够有效地处理大量的消息数据,当 Flink 与 Kafka 相结合时,系统的整体性能和功能得到了显著的提升。
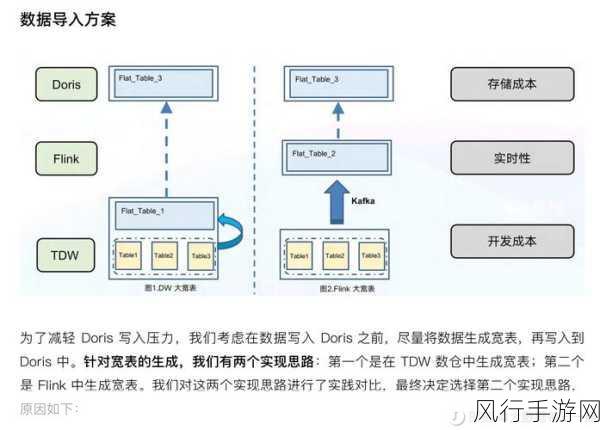
Flink 连接 Kafka 实现了实时数据的高效摄入和处理,Kafka 作为数据源,能够源源不断地向 Flink 提供实时的数据流,使得系统能够快速响应和处理最新的数据变化,这种实时性对于诸如在线监控、实时推荐等对时效性要求极高的应用场景来说至关重要。
两者的连接增强了系统的容错能力,Flink 本身具备强大的容错机制,而 Kafka 的数据持久化特性又为数据的可靠存储提供了保障,即使在系统出现故障或异常的情况下,也能够通过恢复机制从 Kafka 中重新获取数据,确保数据处理的连续性和准确性。

Flink 连接 Kafka 并非毫无挑战,首先是资源配置的问题,为了保证高效的处理和数据传输,需要对 Flink 和 Kafka 的资源进行合理的分配和优化,否则可能会出现资源竞争或不足的情况,影响系统的性能,数据一致性也是需要关注的重点,在数据从 Kafka 传输到 Flink 进行处理的过程中,可能会由于网络延迟、数据丢失等原因导致数据不一致,这就需要采取相应的措施来保证数据的准确性和完整性。
为了充分发挥 Flink 连接 Kafka 的优势,同时应对可能出现的问题,我们需要在系统设计和部署过程中进行精心的规划和配置,根据数据量和处理需求合理调整 Flink 的并行度、优化 Kafka 的分区策略等。
Flink 连接 Kafka 为系统带来了显著的优势,但也需要我们认真对待其中可能存在的挑战,通过合理的设计和优化,实现系统的高效稳定运行,为大数据处理和应用提供有力的支持。