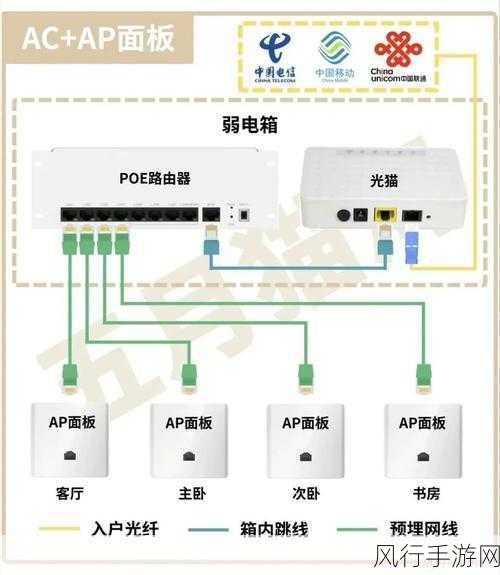
在当今数字化的时代,数据的重要性不言而喻,而 ArangoDB 作为一款备受关注的数据库,其数据复制因子的设置更是关乎数据的安全性、可用性和性能,究竟为何要对 ArangoDB 的数据复制因子进行设置呢?
ArangoDB 中的数据复制因子决定了数据副本的数量,这并非是一个随意设定的参数,而是需要综合考虑多种因素。
从数据安全性的角度来看,如果复制因子设置过低,一旦某个节点出现故障,可能会导致数据丢失的风险增加,相反,较高的复制因子能在多个副本中保存数据,即使某个副本损坏或丢失,仍有其他副本可用,从而大大提高了数据的可靠性和容错能力。
在性能方面,复制因子的设置也有着显著的影响,较高的复制因子意味着在写入数据时需要将数据同步到更多的副本中,这可能会增加写入操作的延迟,在读取数据时,却可以从多个副本中选择,从而提高读取的并发性能,需要根据系统的读写比例和对性能的要求来权衡复制因子的设置。
系统的可用资源也是决定复制因子的重要因素之一,如果系统的硬件资源充足,能够支持更多的数据副本同步操作,那么可以适当提高复制因子,但如果资源有限,过高的复制因子可能会导致系统负载过重,影响整体性能。
业务需求也是设置复制因子时不可忽视的一点,对于一些对数据准确性和可用性要求极高的关键业务,可能需要较高的复制因子来确保数据的完整性和随时可用性,而对于一些非关键业务,较低的复制因子可能就能够满足需求。
ArangoDB 数据复制因子的设置是一个需要综合考虑多方面因素的复杂问题,在实际应用中,需要根据数据安全性、性能需求、可用资源以及业务特点等因素进行权衡和优化,以找到最适合自身业务场景的复制因子设置,从而充分发挥 ArangoDB 的优势,为业务的稳定运行和发展提供有力的支持。