Hive 数据仓库在当今的大数据处理中扮演着至关重要的角色,确保其数据的安全性和可用性是每个数据团队都必须面对的重要任务,而数据备份则是保障数据安全的关键环节之一。
Hive 数据仓库的数据备份并非一项简单的任务,它需要综合考虑多种因素和采用合适的技术手段,在进行数据备份时,需要明确备份的目标和策略,是为了应对系统故障、人为错误,还是为了满足法规合规要求?不同的目标将决定备份的频率、保留周期以及备份数据的存储位置等关键参数。
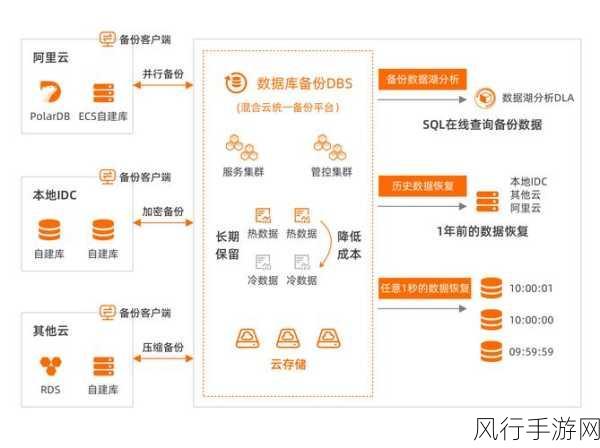
选择合适的备份工具和技术也是至关重要的,常见的备份工具包括 Hadoop 生态系统中的 DistCp 命令、第三方的备份软件等,DistCp 命令可以高效地在 Hadoop 集群之间复制数据,但在配置和使用时需要注意一些细节,比如网络带宽的限制、数据一致性的保障等,第三方备份软件则通常提供更友好的用户界面和更强大的功能,但可能需要一定的成本投入。
要注意备份数据的存储介质和位置,备份数据可以存储在本地磁盘、网络存储设备或者云存储服务中,本地磁盘存储速度快,但容量有限且存在单点故障风险;网络存储设备提供了较大的容量和较好的扩展性,但成本相对较高;云存储服务则具有灵活的扩展性和高可用性,但需要考虑数据传输的费用和安全性。
在备份过程中,数据的压缩和加密也是需要考虑的因素,压缩可以减少备份数据的存储空间,提高备份和恢复的效率;加密则可以保障备份数据的安全性,防止数据泄露。
建立有效的备份验证和恢复测试机制也是必不可少的,定期对备份数据进行验证,确保其完整性和可用性,并且要定期进行恢复测试,模拟实际的故障场景,检验恢复过程是否顺利,恢复的数据是否准确无误。
Hive 数据仓库的数据备份是一个复杂但至关重要的任务,需要综合考虑多个方面的因素,选择合适的备份策略、工具和技术,并建立完善的验证和测试机制,以确保数据的安全和业务的连续性,只有这样,才能在面对各种意外情况时,迅速有效地恢复数据,保障业务的正常运行。