在当今数字化时代,数据的规模和复杂性不断增长,HBase 作为一种广泛应用的分布式数据库,在处理海量数据方面发挥着重要作用,当面临大数据量导出的需求时,我们需要采取一系列有效的策略和技术来确保高效、准确地完成任务。
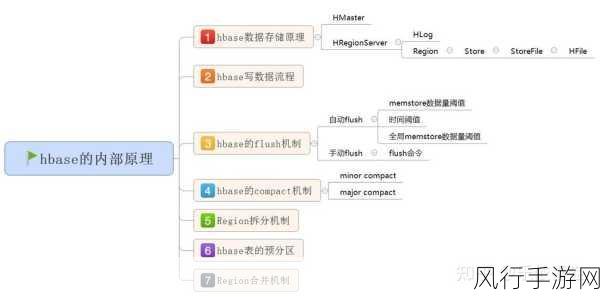
HBase 中的数据导出并非一项简单的操作,特别是在数据量巨大的情况下,这需要我们对 HBase 的架构和特性有深入的理解,同时还需要掌握一些关键的技巧和工具。
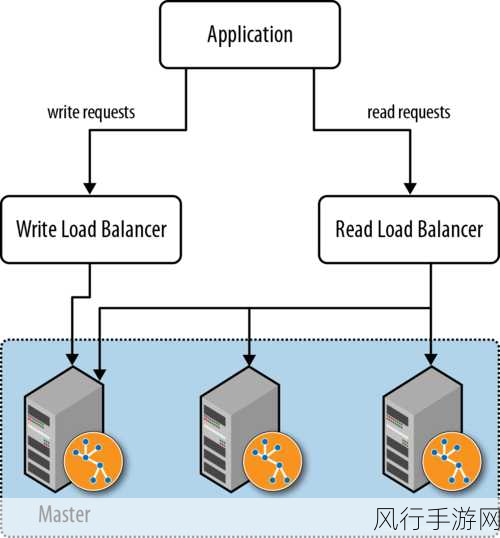
从数据导出的流程来看,我们首先要明确导出的目标和需求,是要将全部数据导出,还是只针对特定的表、列族或时间段的数据进行导出?明确目标有助于我们规划后续的操作步骤。
在选择导出工具时,需要根据实际情况进行权衡,常见的 HBase 导出工具包括 Export 命令、MapReduce 作业以及第三方工具等,Export 命令相对简单易用,但在处理大规模数据时可能性能受限,MapReduce 作业则能够充分利用分布式计算的优势,适用于处理超大规模的数据,而第三方工具可能在某些特定场景下提供更灵活和高效的解决方案。
优化 HBase 表的设计也能对数据导出产生积极影响,合理的分区策略、合适的列族设计以及索引的运用,都可以提高数据读取和导出的效率。
在实际操作中,还需要关注系统资源的使用情况,确保有足够的内存、CPU 和网络带宽来支持数据导出过程,避免因资源不足导致的性能下降或失败。
对导出的数据进行压缩也是一个不错的选择,压缩不仅可以减少数据量,降低存储和传输成本,还能提高导出和传输的速度。
处理 HBase 大数据量导出是一个综合性的任务,需要我们从多个方面进行考虑和优化,只有充分了解 HBase 的特性,结合实际需求选择合适的方法和工具,并注重系统资源的合理配置和数据的优化处理,才能高效、顺利地完成大数据量导出的工作,为数据的进一步分析和应用提供有力支持。