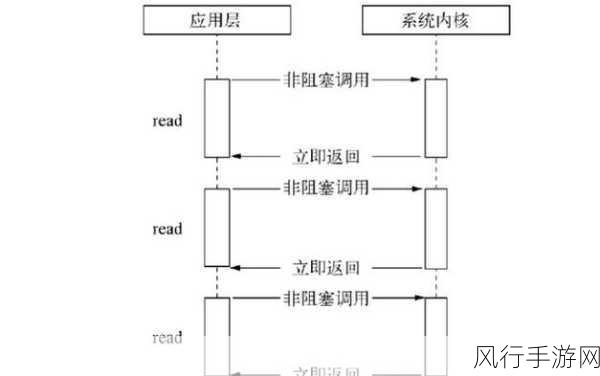
Hadoop 作为大数据处理领域的重要框架,其各个组件的性能和稳定性至关重要,DataNode 在整个 Hadoop 生态系统中扮演着存储数据块的关键角色,Hadoop DataNode 能否自动修复呢?这是一个值得深入探讨的问题。
DataNode 是 Hadoop 分布式文件系统(HDFS)中的重要组成部分,它负责实际存储数据块,并向 NameNode 报告其存储状态,当 DataNode 出现故障或数据损坏时,会对整个 Hadoop 集群的正常运行产生影响。
从技术层面来看,Hadoop 为 DataNode 提供了一定程度的自动修复机制,当 DataNode 检测到数据块损坏时,它会尝试从其他副本中恢复数据,这种自动恢复机制在一定程度上减少了人工干预的需求,提高了系统的可靠性和容错性。
Hadoop DataNode 的自动修复并非是万能的,在某些复杂的情况下,自动修复可能无法完全解决问题,如果多个 DataNode 同时出现故障,或者数据损坏程度严重,自动修复可能无法有效地恢复数据。
Hadoop DataNode 的自动修复还受到一些因素的限制,网络带宽、存储资源等,如果网络带宽不足,数据恢复的速度可能会受到影响;如果存储资源紧张,可能无法为数据恢复提供足够的空间。
为了提高 Hadoop DataNode 的自动修复能力,我们可以采取一些措施,优化 Hadoop 集群的配置,确保有足够的资源来支持自动修复过程,加强对 DataNode 的监控和预警,及时发现潜在的问题,并在问题恶化之前采取相应的措施。
Hadoop DataNode 具备一定的自动修复能力,但在实际应用中,我们不能完全依赖它,通过合理的配置、有效的监控和及时的人工干预,我们可以更好地保障 Hadoop 集群的稳定运行,确保数据的安全性和可靠性,对于 Hadoop 管理员和开发者来说,深入了解 DataNode 的自动修复机制,并根据实际情况进行优化和管理,是非常重要的工作。