在 C 语言的世界里,Set(集合)是一种非常有用的数据结构,其元素的访问方式却并非一目了然,要深入理解 C 语言中 Set 元素的访问方式,需要我们从多个角度进行剖析。
Set 元素的访问并非像数组那样通过简单的索引就能完成,这是因为 Set 通常是以特定的算法和数据结构来实现的,以确保元素的唯一性和高效的操作。
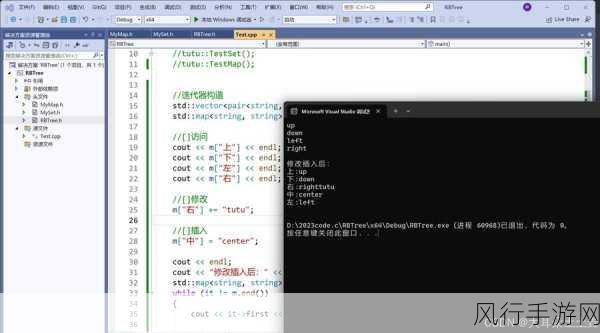
我们先来看一下常见的 Set 实现方式,比如基于哈希表或者二叉搜索树,对于基于哈希表的 Set,访问元素时需要通过计算元素的哈希值来定位其在表中的位置,而对于基于二叉搜索树的 Set,则需要通过比较元素的值来沿着树的节点进行查找。
在实际编程中,我们可以使用相应的函数或者方法来访问 Set 中的元素,这些函数通常会根据具体的实现方式来进行内部的查找和操作。
需要注意的是,Set 元素的访问效率也会受到其规模和元素分布的影响,当 Set 中的元素数量较大时,访问操作可能会花费相对较多的时间。
为了提高访问效率,我们可以采取一些优化策略,合理选择 Set 的实现方式,根据数据的特点和访问模式来决定是使用哈希表还是二叉搜索树,对于频繁访问的 Set,可以考虑进行缓存或者预计算,以减少实际的查找操作。
理解 C 语言中 Set 元素的访问方式是掌握高效编程的重要一环,只有深入了解其背后的原理和机制,我们才能在实际应用中灵活运用,编写出高效、可靠的代码。