HBase 作为一种分布式的大数据存储系统,在处理海量数据时,其性能优化至关重要,预分区策略是一个备受关注的话题,HBase 预分区能否真的提高查询性能呢?
预分区是指在创建表时,事先将数据空间划分成多个区域,这样做的好处是显而易见的,当数据插入时,能够更均匀地分布在各个分区中,避免了数据集中在少数分区导致的热点问题,热点问题一旦出现,会使得某些分区的负载过高,从而影响查询性能。
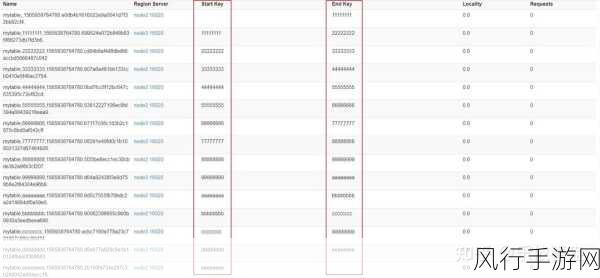
从数据存储的角度来看,预分区使得数据的存储更加有序和规律,查询操作在这种有序的存储结构中能够更高效地定位所需的数据,在范围查询中,如果分区设置合理,查询可以直接定位到相关的分区,减少了不必要的数据扫描,大大提高了查询的效率。
预分区还能优化数据的读写并发性能,不同的分区可以同时进行读写操作,互不干扰,这意味着在高并发的场景下,系统能够更好地应对大量的并发请求,提高整体的吞吐量。
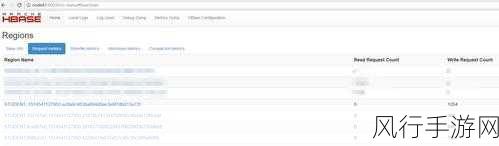
预分区并非是一种一劳永逸的解决方案,如果预分区的设置不合理,比如分区数量过少或者分区边界划分不当,可能会适得其反,降低查询性能。
分区数量过少,可能导致数据分布不均匀,仍然出现热点问题;分区边界划分不当,则可能使得查询需要跨越多个分区,增加了查询的复杂性和时间成本。
要想通过预分区来提高 HBase 的查询性能,需要对业务数据的特点和查询模式有深入的理解,根据数据的分布规律和查询的频繁范围,合理地设置分区数量和边界,才能充分发挥预分区的优势。
HBase 预分区在合理规划和配置的情况下,确实能够显著提高查询性能,但这需要我们在实践中不断摸索和优化,以找到最适合具体业务场景的预分区方案。