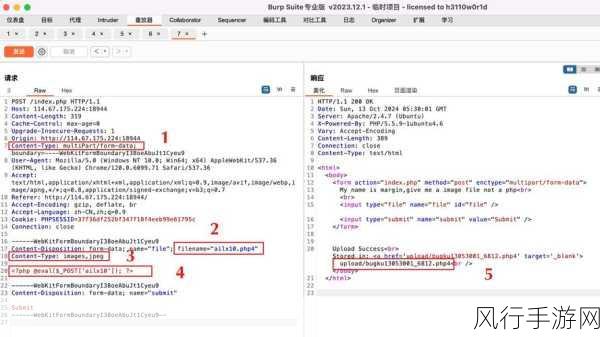
在当今大数据处理领域,Hive 和 HBase 是两个备受关注的技术框架,它们在数据存储和处理方面都有着各自独特的特点和优势,但在性能方面却存在着一定的差异。
Hive 是基于 Hadoop 的数据仓库工具,它主要用于大规模数据的离线分析和处理,Hive 提供了类似于 SQL 的查询语言 HiveQL,使得熟悉传统关系型数据库的用户能够轻松上手,在数据存储方面,Hive 通常将数据存储在 HDFS 上,以表的形式进行组织,Hive 的查询执行速度相对较慢,尤其是对于复杂的查询和实时性要求较高的场景,可能无法满足需求。
HBase 则是一个面向列的分布式数据库,适用于实时读写、随机访问大规模数据的场景,HBase 能够在毫秒级别响应数据请求,具有出色的实时性能,它的数据存储方式是按照列族进行组织,并且通过键值对的方式进行数据存储和访问。
从数据存储结构来看,Hive 采用的是基于行的存储方式,这在处理大规模数据时可能会导致数据扫描的开销较大,而 HBase 基于列存储,能够有效地减少数据读取的范围,提高查询效率。
在数据处理方面,Hive 更擅长处理批处理任务,通过 MapReduce 等计算框架来执行查询操作,这种方式在处理大规模数据时具有较好的扩展性,但在实时性方面表现不佳,HBase 则支持实时的数据插入、更新和查询,能够快速响应用户的操作请求。
在数据一致性方面,Hive 对数据一致性的要求相对较低,更注重数据的分析和处理结果,而 HBase 则需要保证较高的数据一致性,以确保数据的准确性和完整性。
Hive 和 HBase 在性能方面各有优劣,在实际应用中,需要根据具体的业务需求和场景来选择合适的技术框架,如果是大规模数据的离线分析和处理,Hive 可能是一个不错的选择;而对于实时性要求较高的业务场景,HBase 则更能发挥其优势。
深入了解 Hive 和 HBase 的性能特点,能够帮助我们在大数据处理中做出更加明智的技术选型,从而更好地满足业务需求,提升数据处理的效率和质量。