在当今数字化的时代,数据处理和分析变得日益重要,而 Cypher 作为一种强大的图数据库查询语言,其聚合函数在数据处理中发挥着关键作用,特别是条件聚合,它能够帮助我们从海量的数据中提取出有价值的信息。
Cypher 中的聚合函数允许我们对一组数据进行计算,并返回一个单一的结果,条件聚合则在此基础上增加了筛选条件,使得我们能够更精准地聚焦于特定的数据子集进行聚合操作。
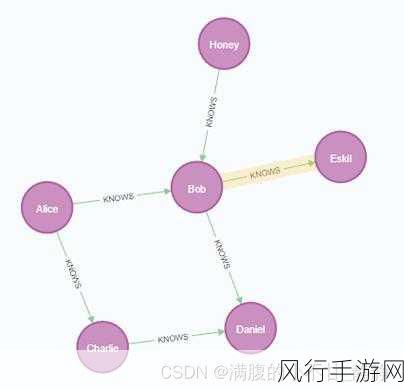
Cypher 聚合函数中的条件聚合到底是如何实现的呢?让我们逐步深入了解。
我们先来看看常见的 Cypher 聚合函数,COUNT、SUM、AVG、MIN 和 MAX 等,这些函数分别用于计算数据的数量、总和、平均值、最小值和最大值,而当我们要进行条件聚合时,就需要结合 WHERE 子句来指定筛选条件。
如果我们有一个包含员工信息的图数据库,其中包括员工的年龄和工资等属性,现在我们想要计算年龄大于 30 岁的员工的平均工资,就可以使用如下的 Cypher 查询语句:
MATCH (e:Employee) WHERE e.age > 30 RETURN AVG(e.salary) AS average_salary
在这个例子中,MATCH 子句用于指定要查找的节点类型(即员工节点),WHERE 子句用于设置条件(年龄大于 30 岁),RETURN 子句中的 AVG 函数则用于计算符合条件的员工工资的平均值,并将结果命名为 average_salary。
条件聚合不仅可以基于节点的属性进行筛选,还可以结合关系的属性来实现更复杂的聚合计算,如果我们的图数据库中存在员工与部门之间的关系,并且关系中包含了员工在该部门的工作年限等属性,我们可以计算特定部门中工作年限超过 5 年的员工的工资总和。
MATCH (e:Employee)-[r:WORKS_IN]->(d:Department) WHERE r.years_of_work > 5 AND d.name = 'Marketing' RETURN SUM(e.salary) AS total_salary
通过上述示例可以看出,Cypher 的条件聚合功能为我们提供了强大而灵活的数据处理能力,使我们能够根据具体的业务需求从图数据库中提取出有意义的统计信息。
在实际应用中,合理运用 Cypher 的条件聚合函数能够帮助我们解决许多复杂的数据问题,为决策提供有力的支持,但同时,也需要对数据结构和业务逻辑有清晰的理解,以确保编写的查询语句能够准确地获取所需的数据。
Cypher 聚合函数中的条件聚合是一项强大而实用的功能,掌握它将有助于我们更高效地处理和分析图数据库中的数据,挖掘出隐藏在数据背后的价值和洞察,无论是进行数据分析、业务决策还是构建复杂的应用系统,都能从中受益匪浅,希望通过本文的介绍,能够让您对 Cypher 条件聚合有更深入的认识和理解,从而在实际工作中更加得心应手地运用这一技术。