探索 Sqoop 与 HBase 增量导入的可行性
Sqoop 作为一款在大数据领域中广泛应用的数据迁移工具,与 HBase 相结合时,能否支持增量导入是许多数据处理从业者关心的重要问题。
HBase 作为一种分布式的 NoSQL 数据库,具有高扩展性和高性能的特点,而 Sqoop 则主要用于在关系型数据库和 Hadoop 生态系统之间进行数据传输。

在实际的数据处理场景中,增量导入的需求常常出现,Sqoop 能够支持对 HBase 的增量导入,无疑将大大提高数据处理的效率和灵活性,Sqoop 到底能不能实现这一功能呢?
从技术原理上分析,Sqoop 本身是具备一定的增量导入能力的,它可以通过识别数据的变化,如新增、修改和删除的记录,来实现对目标数据库的增量更新,要在 HBase 中实现增量导入并非一帆风顺。
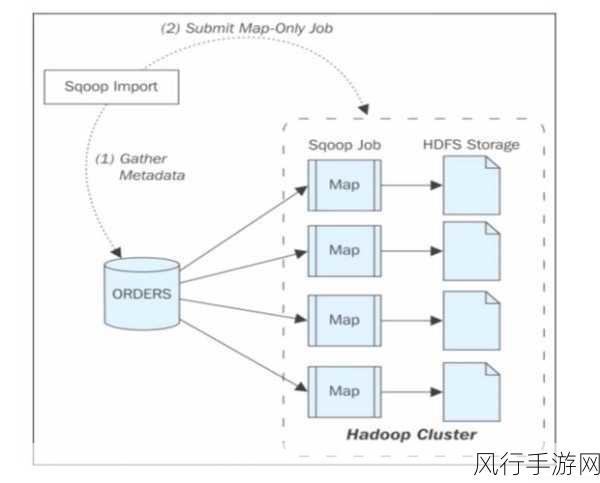
HBase 的架构和数据存储方式与传统的关系型数据库有所不同,HBase 是基于列存储的,并且数据分布在多个节点上,这就给 Sqoop 的增量导入带来了一些挑战,如何准确地识别 HBase 中数据的变化,如何高效地将增量数据写入到合适的位置等。
为了实现 Sqoop 对 HBase 的增量导入,需要对 Sqoop 的配置进行精心的调整和优化,还需要对 HBase 的表结构和数据分布有深入的了解,以便能够更好地处理增量数据。
还需要考虑数据的一致性和完整性,在增量导入过程中,如何确保新导入的数据与原有数据的一致性,如何处理可能出现的数据冲突,都是需要认真思考和解决的问题。
Sqoop 理论上是能够支持对 HBase 的增量导入的,但在实际应用中,需要综合考虑多种因素,进行充分的测试和优化,以确保增量导入的效果和数据的质量。
随着大数据技术的不断发展,Sqoop 和 HBase 也在不断演进和完善,相信在未来,它们之间的集成会更加紧密,为数据处理带来更多的便利和高效。
对于从事大数据开发和数据处理的人员来说,深入研究和掌握 Sqoop 与 HBase 增量导入的技术,将有助于提升自身的技术水平和解决实际问题的能力,为企业创造更大的价值。