深入探究 Kafka Queue 的局限性
Kafka 作为一种强大的分布式消息队列系统,在处理大规模数据和高并发场景中表现出色,就像任何技术一样,Kafka Queue 也并非完美无缺,存在着一些限制。
Kafka Queue 的分区分配策略可能会带来一些挑战,在默认情况下,Kafka 会根据一定的算法将分区分配给消费者组中的消费者,但这种分配方式可能导致某些消费者负载过重,而另一些消费者相对空闲,从而影响整体的处理效率,当消费者数量发生变化时,重新平衡分区的过程可能会带来短暂的性能下降。

消息的顺序保证也是 Kafka Queue 中的一个复杂问题,虽然 Kafka 可以在单个分区内保证消息的顺序,但在多个分区的情况下,消息的全局顺序就无法得到保证,这对于一些对消息顺序有严格要求的应用场景来说,可能会造成困扰。
Kafka Queue 的存储管理也需要谨慎处理,由于 Kafka 会持久化消息,如果不进行适当的配置和监控,可能会导致存储空间的快速增长,特别是在高吞吐量的环境中,大量的消息积累可能会占用大量的磁盘空间,甚至影响系统的性能。
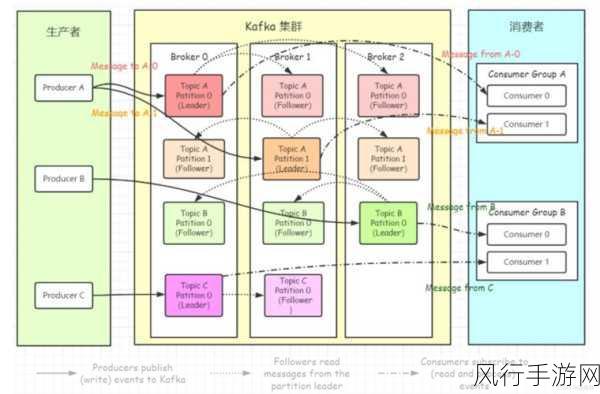
Kafka 的复杂性也是一个限制因素,对于初次接触和使用的开发者来说,理解和配置 Kafka 的各种参数、主题、分区等概念可能需要花费一定的时间和精力,在出现问题时,排查和解决故障也相对较为复杂。
还有一个需要注意的点是,Kafka 的性能优化需要对系统有深入的了解和精细的调整,调整缓冲区大小、复制因子、消息压缩算法等参数,都需要根据具体的业务场景和硬件环境进行仔细的权衡和测试。
尽管 Kafka Queue 存在这些限制,我们不能忽视它在大数据处理和分布式系统中的重要地位和优势,通过合理的规划、配置和使用,我们可以最大程度地发挥 Kafka 的作用,同时有效地应对其存在的局限性,在实际应用中,结合具体的业务需求和技术架构,综合考虑各种因素,选择最适合的消息队列解决方案,才能实现系统的高效稳定运行。