探索 HBase 分区的数据分布策略
HBase 作为一款强大的分布式数据库,其分区机制在数据管理和性能优化方面起着至关重要的作用,合理的分区设计能够实现高效的数据分布,提升数据读写的性能。
HBase 的分区是将大规模的数据表按照特定的规则划分为多个区域(Region),每个 Region 包含一定范围的数据,这种分区方式有助于将数据分散存储在不同的节点上,避免单点故障和数据热点问题。
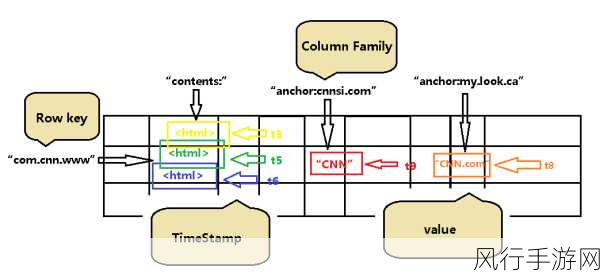
HBase 分区是如何进行数据分布的呢?这涉及到多个关键因素和策略。
RowKey 的设计对于数据分布至关重要,RowKey 决定了数据在分区中的位置,一个好的 RowKey 设计应该考虑数据的访问模式和分布特性,RowKey 设计不合理,可能会导致数据倾斜,即某些 Region 中的数据量远远大于其他 Region,从而影响系统性能。
预分区策略也是影响数据分布的重要因素,通过提前规划好分区的边界,可以更好地控制数据在不同 Region 中的分布,预分区可以根据数据的特点、预期的访问模式以及数据量的增长趋势来进行。
HBase 还支持动态分区,在数据写入过程中,如果某个 Region 的大小超过了一定的阈值,系统会自动将其分裂为两个或更多的 Region,以保证数据的均匀分布,这种动态调整机制能够适应数据量的不断变化,但也需要合理设置分裂的阈值,避免过于频繁的分裂操作带来的性能开销。
HBase 还可以结合集群的配置和节点的负载情况来优化数据分布,将负载较高的 Region 迁移到负载较低的节点上,以实现负载均衡。
在实际应用中,要实现高效的数据分布,需要综合考虑上述因素,并根据具体的业务需求和数据特点进行针对性的优化,不断监测和分析数据分布的情况,及时调整分区策略,以确保 HBase 系统能够始终保持良好的性能和稳定性。
HBase 分区的数据分布是一个复杂而关键的问题,需要深入理解其原理和机制,并结合实际情况进行精心设计和优化,才能充分发挥 HBase 的优势,为业务提供可靠高效的数据存储和访问服务。