深度解析 Spark SortBy 在处理大数据量时的卓越策略
在当今数字化时代,数据量呈爆炸式增长,如何高效地处理大数据量成为了众多企业和开发者面临的关键挑战,而 Spark 作为一款强大的大数据处理框架,其中的 SortBy 操作在应对大数据量时展现出了出色的性能和灵活性。
Spark SortBy 是一种用于对数据进行排序的操作,它能够根据指定的字段对大规模的数据进行排序,从而满足各种业务需求,在处理大数据量时,其背后的算法和优化机制发挥了至关重要的作用。
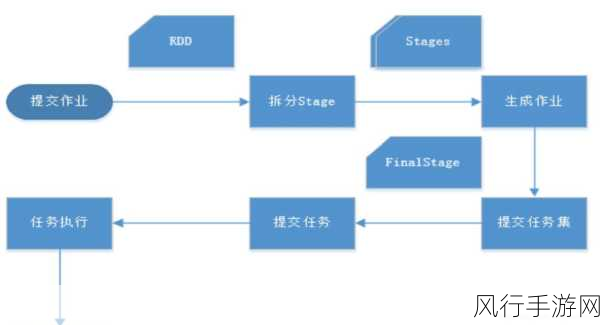
Spark SortBy 之所以能够在大数据量处理中表现出色,主要得益于其分布式计算的架构,它将数据分布在多个节点上进行并行处理,大大提高了处理速度,Spark 还采用了高效的内存管理和数据分区策略,进一步优化了排序的性能。
在实际应用中,为了充分发挥 Spark SortBy 的优势,我们需要合理地设置相关参数,调整分区数量可以影响数据的分布和并行处理的效率,选择合适的排序算法也能对性能产生显著影响。
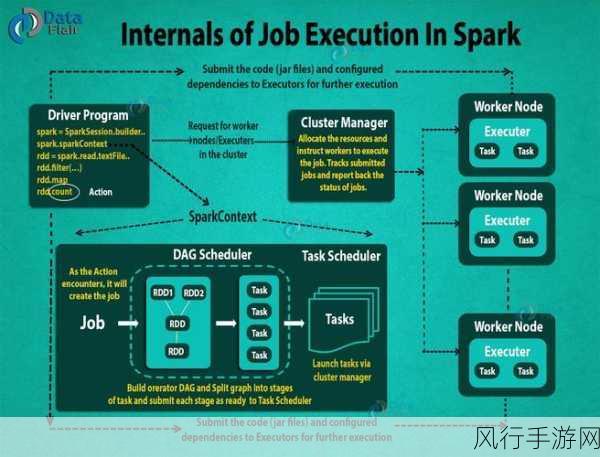
数据的特点也会对 Spark SortBy 的处理效果产生影响,如果数据存在大量重复值,可能需要采用特殊的处理方式来提高排序效率。
Spark SortBy 在处理大数据量方面具有强大的能力,但要实现最佳性能,需要综合考虑多个因素,包括数据特点、参数设置、算法选择等,只有深入理解和熟练运用这些技巧,才能在大数据处理的浪潮中驾驭 Spark SortBy,为业务发展提供有力的支持。