探索 Python 中的数据压缩算法
在当今数字化的时代,数据的处理和存储成为了至关重要的环节,而数据压缩算法作为一种有效的手段,能够在不损失数据关键信息的前提下,显著减少数据的存储空间和传输带宽,Python 作为一种功能强大的编程语言,为实现各种数据压缩算法提供了丰富的工具和库。
在 Python 中,常见的数据压缩算法包括哈夫曼编码、LZ77 算法和 LZ78 算法等。
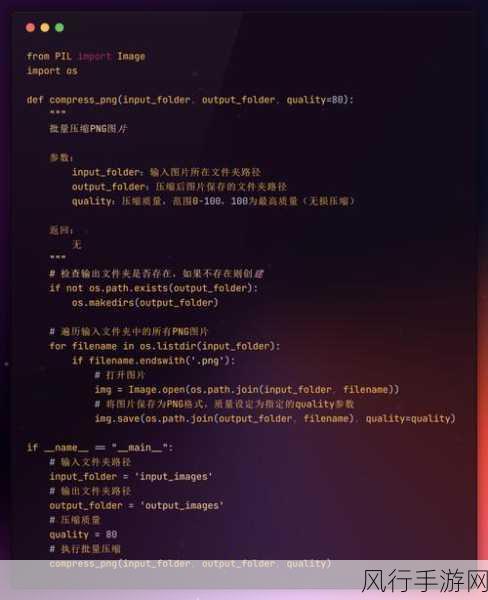
哈夫曼编码是一种基于字符出现频率构建最优编码的算法,它通过对数据中字符的频率进行统计,为频繁出现的字符分配较短的编码,为较少出现的字符分配较长的编码,从而实现数据的压缩,在 Python 中,可以使用自定义的代码来实现哈夫曼编码,通过构建哈夫曼树和生成编码表,对原始数据进行编码和解码操作。
LZ77 算法是一种基于字典的压缩算法,它通过维护一个滑动窗口和一个前向缓冲区,在窗口中查找与缓冲区中数据匹配的字符串,并使用指针和长度来表示匹配部分,从而实现压缩,Python 中的一些库,如zlib 库,提供了对 LZ77 算法的支持,可以方便地对数据进行压缩和解压缩。

LZ78 算法则是 LZ77 算法的改进版本,它在编码过程中构建字典,以更高效的方式表示数据中的重复模式。
除了上述算法,还有其他一些在特定场景下表现出色的数据压缩算法,如算术编码、游程编码等。
在实际应用中,选择合适的数据压缩算法取决于多个因素,如数据的特点、压缩比的要求、计算资源的限制等,如果数据具有较高的重复性,LZ 系列算法可能会有较好的效果;如果对压缩比要求较高,算术编码可能是一个不错的选择。
Python 为数据压缩算法的实现和应用提供了强大的支持,通过合理选择和运用合适的算法,可以有效地优化数据存储和传输,提高系统的性能和效率,无论是处理大规模的文本数据、图像数据还是其他类型的数据,Python 中的数据压缩算法都能发挥重要的作用,为我们的数据处理工作带来便利和效益。