Spark2 与 Spark3,未来趋势的深度剖析
当我们探讨 Spark2 和 Spark3 哪个更符合未来趋势时,这无疑是一个引人深思的话题,在大数据处理和分析领域,Spark 一直占据着重要的地位,而其版本的不断更新也反映了技术的不断演进和市场需求的变化。
Spark2 在过去的一段时间里为数据处理带来了显著的改进和优化,它在性能、稳定性和功能方面都有不错的表现,使得许多企业能够高效地处理大规模的数据,随着技术的飞速发展和数据量的持续爆炸式增长,对数据处理框架的要求也越来越高。
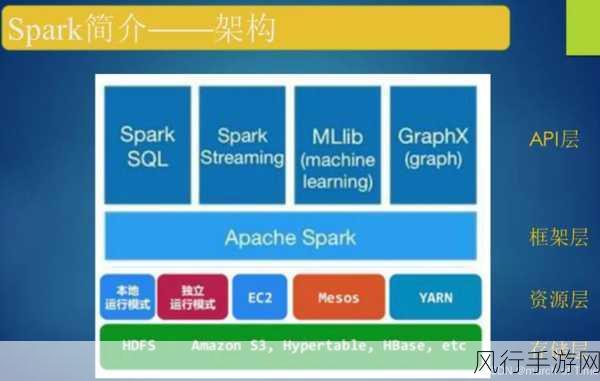
Spark3 的出现正是为了应对这些新的挑战和需求,它在多个方面进行了重大的改进和创新,在性能方面,Spark3 对执行引擎进行了优化,提高了数据处理的速度和效率,尤其是在处理大规模数据和复杂计算任务时,其性能优势更为明显。
从功能角度来看,Spark3 引入了一些新的特性,如自适应查询执行、动态分区裁剪等,这些功能使得数据处理更加灵活和智能,它能够根据数据的分布和计算的需求,自动调整执行计划,从而获得更好的性能和资源利用效率。
在兼容性和扩展性方面,Spark3 也表现出色,它能够更好地与其他大数据技术和框架进行集成,为构建完整的大数据生态系统提供了更有力的支持。
我们不能简单地认为 Spark3 就一定完全优于 Spark2,在某些特定的场景和应用中,Spark2 可能仍然是更合适的选择,如果企业的现有系统和架构已经基于 Spark2 进行了深度的定制和优化,迁移到 Spark3 可能会带来较大的成本和风险。
判断 Spark2 和 Spark3 哪个更符合未来趋势,不能一概而论,这需要根据具体的业务需求、技术环境和发展战略来综合考虑,但从技术发展的大方向来看,Spark3 在性能、功能和扩展性等方面的优势,使其更有可能在未来的大数据处理领域中占据主导地位,不过,无论选择哪个版本,持续的技术创新和优化都是保持竞争力的关键,只有不断适应市场的变化和需求,才能在大数据的浪潮中乘风破浪,勇往直前。