掌握 SparkSQL 优化,高效降低资源消耗
在当今大数据处理领域,SparkSQL 凭借其强大的功能和出色的性能表现,成为了众多数据工程师和分析师的得力工具,在实际应用中,若不进行合理的优化,可能会导致资源消耗过高,影响系统的整体效率和成本,如何有效地对 SparkSQL 进行优化以减少资源消耗呢?
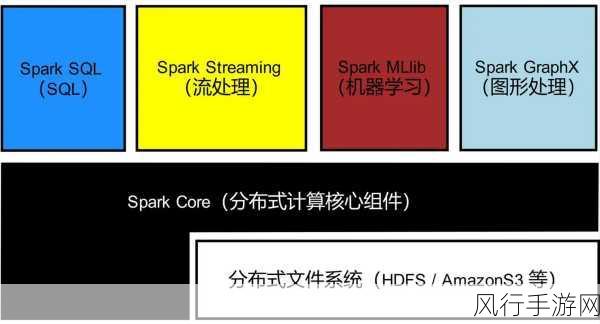
要实现 SparkSQL 优化以降低资源消耗,深入理解其工作原理是关键,SparkSQL 是基于 Spark 计算框架构建的,它将结构化数据处理转化为分布式计算任务,在这个过程中,数据的分布、存储格式以及计算逻辑的设计都会对资源消耗产生重要影响。
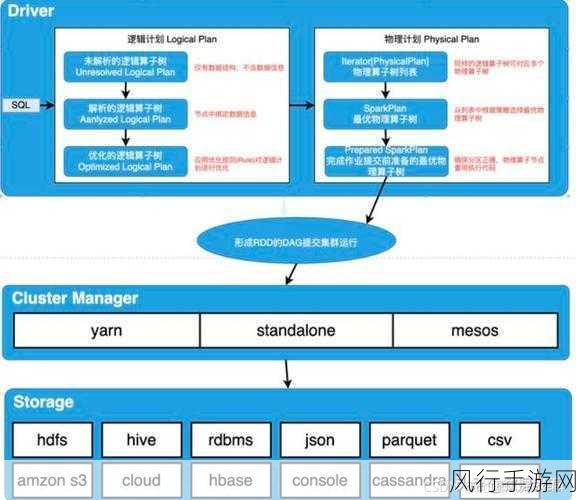
我们从几个重要方面来探讨优化策略。
其一,优化数据存储格式,合适的数据存储格式能够显著提高数据读取和处理的效率,对于列式存储格式 Parquet 和 ORC,它们在处理大规模数据时具有良好的压缩比和读取性能,通过将数据存储为这些格式,可以减少磁盘 I/O 和内存消耗。
其二,合理设置分区,分区是将数据划分为多个独立的子集,以便在处理时能够并行操作,根据数据的特点和查询模式,选择合适的分区字段和分区策略,能够避免不必要的数据扫描,从而降低资源消耗。
其三,优化查询计划,在编写 SparkSQL 查询语句时,应尽量避免复杂的逻辑和不必要的操作,利用 Spark 的查询优化器,如 CBO(Cost-Based Optimizer),可以根据数据统计信息和查询条件自动生成最优的执行计划。
其四,调整资源配置,根据任务的规模和复杂度,合理配置 Spark 应用的资源,包括内存、CPU 核心数等,避免资源不足导致的任务失败或资源过剩造成的浪费。
还有一些细节方面的优化技巧,对于小表的连接操作,可以采用广播变量的方式,将小表的数据分发到各个节点,减少数据传输开销,再比如,利用缓存机制,将经常使用的数据缓存到内存中,提高重复查询的效率。
SparkSQL 优化以减少资源消耗是一个综合性的工作,需要我们从多个角度入手,结合实际业务需求和数据特点,不断探索和实践,只有这样,才能充分发挥 SparkSQL 的优势,提高数据处理的效率和性价比,为企业的数字化转型提供有力支持。