探究 HBase Phoenix 处理大数据的效能之谜
在当今数字化时代,数据的规模和复杂性呈爆炸式增长,如何高效处理大数据成为了企业和开发者面临的关键挑战,HBase Phoenix 作为一种技术组合,备受关注,但其能否真正高效处理大数据,还需要我们深入探究。
HBase 是一个分布式的、面向列的开源数据库,以其出色的可扩展性和高并发写入能力而闻名,而 Phoenix 则是构建在 HBase 之上的一个 SQL 层,旨在为 HBase 提供更友好的查询接口,使开发者能够使用熟悉的 SQL 语句来操作 HBase 中的数据。
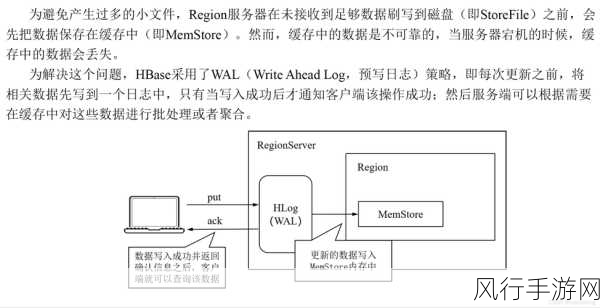
从性能方面来看,HBase Phoenix 在处理大数据时具有一定的优势,HBase 的分布式架构能够轻松应对海量数据的存储和快速写入,Phoenix 的引入则使得复杂的查询操作变得更加便捷和高效,对于大规模的数据扫描和聚合操作,HBase Phoenix 能够充分利用分布式计算的能力,将任务分配到多个节点上并行处理,从而大大缩短查询时间。
HBase Phoenix 并非在所有场景下都是完美的解决方案,在数据一致性要求极高的场景中,可能会面临一些挑战,由于 HBase 本身是最终一致性模型,而 Phoenix 虽然提供了类似关系型数据库的查询接口,但在某些复杂的事务处理上,可能无法完全满足传统关系型数据库的强一致性要求。

HBase Phoenix 的配置和优化也是一个关键因素,要充分发挥其处理大数据的效能,需要对 HBase 的集群配置、内存管理、数据分区等方面进行精细的调整,同时对 Phoenix 的查询计划、索引使用等进行优化,这对于运维人员和开发人员的技术水平提出了较高的要求。
在实际应用中,还需要考虑与其他技术框架的集成,与数据采集工具、数据处理引擎、数据可视化平台等的无缝对接,以构建完整的数据处理流水线,如果集成过程中出现兼容性问题或者性能瓶颈,可能会影响整个系统的运行效率。
HBase Phoenix 在处理大数据方面具有很大的潜力,但也需要根据具体的业务需求和场景进行合理的选型、配置和优化,只有在充分了解其特点和局限性的基础上,才能更好地利用这一技术组合,实现高效的数据处理和价值挖掘,随着技术的不断发展和创新,相信 HBase Phoenix 会不断完善和提升,为大数据处理领域带来更多的惊喜和突破。