SQL 和 XPath,复杂性的探究与解析
SQL(Structured Query Language)和 XPath(XML Path Language)是在数据处理和查询领域中常用的技术,但它们的复杂性常常引发人们的讨论和思考。
SQL 作为关系型数据库管理系统中最常用的语言,其功能强大且应用广泛,它允许用户执行各种操作,如数据查询、插入、更新和删除,对于初学者来说,SQL 的语法规则和众多的函数可能会让人感到有些棘手,连接多个表进行复杂的关联查询时,需要清晰地理解表之间的关系以及相应的连接条件,复杂的聚合函数和子查询的运用也需要一定的经验和理解才能熟练掌握。
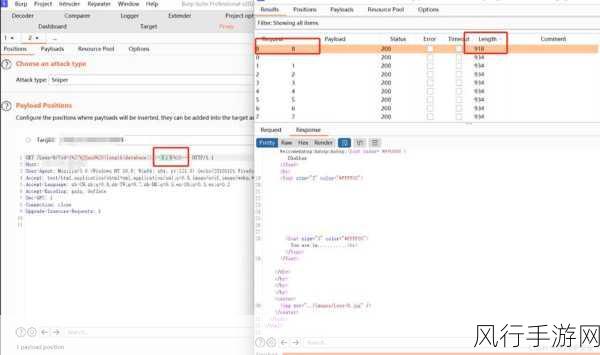
XPath 则主要用于在 XML 文档中定位和选择节点,它提供了一种灵活的方式来遍历 XML 结构并提取所需的信息,XPath 的表达式语法和路径规则可能会给使用者带来一定的挑战,特别是当 XML 文档的结构较为复杂,或者需要进行深度嵌套的节点选择时,编写准确的 XPath 表达式需要对 XML 的层次结构有清晰的认识。
SQL 和 XPath 到底复杂吗?这取决于多个因素,使用者的背景和经验是一个重要的方面,对于已经熟悉编程和数据处理概念的人来说,掌握 SQL 和 XPath 的基本原理可能相对容易,但要达到精通并处理复杂的场景,仍需要不断的实践和学习。
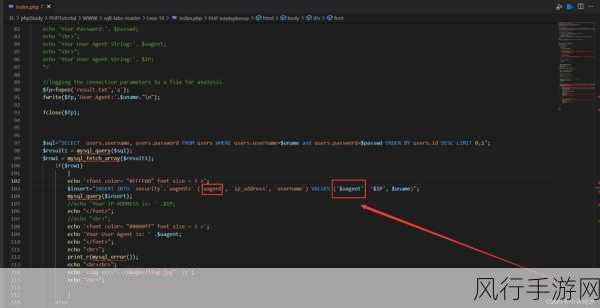
从应用场景来看,如果只是进行简单的数据查询和操作,SQL 和 XPath 并不显得特别复杂,但在处理大规模数据、复杂的业务逻辑或需要与其他技术集成时,它们的复杂性就会逐渐显现出来。
要降低 SQL 和 XPath 的使用难度,良好的学习资源和实践是关键,通过系统的学习教程、实际的项目案例以及与其他开发者的交流,可以帮助我们更好地理解和运用这两种技术。
SQL 和 XPath 具有一定的复杂性,但通过不断的学习和实践,我们能够逐渐克服这些困难,充分发挥它们在数据处理和查询中的强大功能,无论是处理数据库中的关系数据,还是在 XML 文档中精准定位信息,掌握好这两种技术都将为我们的工作和学习带来极大的便利。