探究 Kafka 消息合并对吞吐量的影响
Kafka 作为一种高性能的分布式消息队列,在现代应用架构中扮演着至关重要的角色,而消息合并这一策略,是否真能提升其吞吐量,是一个值得深入探讨的问题。
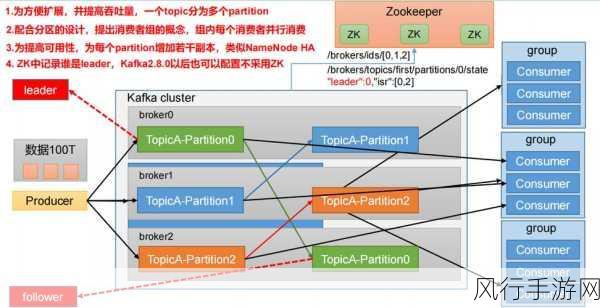
要理解 Kafka 消息合并与吞吐量之间的关系,我们先来看看 Kafka 本身的工作原理,Kafka 采用了分区的方式来存储和处理消息,每个分区都是一个有序的消息队列,消息的发送和消费都是基于这些分区进行的。
消息合并,从直观上理解,就是将多个较小的消息组合成一个较大的消息进行处理,这样做的好处在于减少了网络开销和系统资源的消耗,想象一下,如果每个小消息都需要单独进行网络传输和处理,那么系统的负担将会大大增加,而通过合并消息,可以在一定程度上降低这种开销。
消息合并并非是无条件提升吞吐量的“万能钥匙”,在某些情况下,它可能会带来一些潜在的问题,如果合并的消息过大,可能会导致处理延迟增加,因为在消费端,需要对合并后的大消息进行解析和处理,这可能需要更多的时间和计算资源。
消息合并的策略和实现方式也会对效果产生影响,如果合并的规则不合理,可能会导致消息的顺序混乱,或者丢失一些关键的信息,这对于一些对消息顺序和完整性有严格要求的应用场景来说,是不可接受的。
从实际应用的角度来看,需要根据具体的业务需求和系统环境来评估消息合并是否适合,如果系统的网络带宽是瓶颈,而消息本身较小且数量众多,那么消息合并很可能会带来显著的吞吐量提升,但如果系统的处理能力有限,或者消息的内容和结构比较复杂,就需要谨慎考虑消息合并的必要性。
为了更准确地评估消息合并对吞吐量的影响,可以进行一系列的实验和测试,通过设置不同的消息大小、合并策略和系统参数,观察吞吐量、延迟等关键指标的变化,从而找到最优的配置方案。
Kafka 消息合并在一定条件下能够提升吞吐量,但需要综合考虑各种因素,并通过实际测试来验证其效果,在实际应用中,要根据具体情况灵活选择和优化消息处理策略,以达到最佳的性能和业务需求的平衡。