深入剖析 Spark 数据类型的优劣之处
Spark 作为大数据处理领域的强大工具,其数据类型的选择和运用对于数据处理的效率和效果有着至关重要的影响。
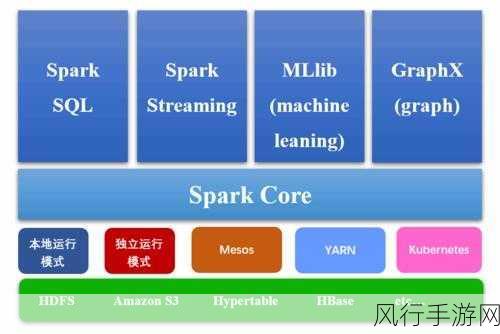
Spark 提供了多种丰富的数据类型,每种类型都有其独特的特点和适用场景,整数类型(Integer)、浮点数类型(Float、Double)、字符串类型(String)等常见基本数据类型,在处理简单的数据时表现出色,使用方便且直观,但在处理复杂的数据结构和关系时,就需要用到更高级的数据类型,如数组(Array)、映射(Map)和结构体(Struct)等。

整数类型在存储和计算整数数值时效率较高,占用的存储空间相对较小,当处理超出其表示范围的整数时,可能会出现数据溢出的问题,浮点数类型则能够处理小数数值,但需要注意精度和舍入误差的问题。
字符串类型在存储和处理文本数据时非常常用,但它的操作相对较为复杂,特别是在进行字符串的比较和搜索时,可能会消耗较多的计算资源。
数组类型允许存储一组相同类型的元素,方便对一组相关数据进行统一处理,但数组的长度在创建时通常需要确定,如果后续需要动态扩展或收缩,操作会比较复杂。
映射类型则适合存储键值对形式的数据,可以快速根据键来查找对应的值,不过,映射的存储空间开销相对较大,特别是当键值对数量较多时。
结构体类型能够将不同类型的字段组合在一起,形成一个复杂的数据结构,使数据的组织更加清晰和有逻辑性,但结构体的定义和使用相对较为复杂,需要对数据结构有清晰的规划。
在实际应用中,选择合适的数据类型需要综合考虑数据的特点、处理需求和性能要求,如果对数据的精度要求较高,就需要选择合适的数值类型;如果数据之间存在复杂的关系,可能需要使用结构体或映射来进行组织。
深入理解 Spark 数据类型的优缺点,能够帮助我们在大数据处理中做出更明智的选择,从而提高数据处理的效率和质量。