Python 网络爬虫技术,规避封禁的有效策略
在当今数字化的时代,网络爬虫技术成为了获取大量数据的重要手段,在使用 Python 进行网络爬虫时,如何防止被封禁成为了一个关键问题。
要防止 Python 网络爬虫被封禁,我们需要从多个方面入手,其一,控制爬取的频率至关重要,如果过于频繁地向目标网站发送请求,很容易引起网站服务器的警觉,从而导致被封禁,合理设置爬取的时间间隔,模拟人类正常的访问行为,是降低被封禁风险的有效方式。
需要尊重网站的规则和政策,许多网站在其“使用条款”或“服务协议”中明确规定了禁止爬虫的相关内容,在进行爬虫之前,务必仔细阅读并遵守这些规定,以避免不必要的麻烦。
对于爬取的数据量,也要进行合理的控制,不要一次性获取过多的数据,以免对网站的正常运行造成负担,在处理数据时,要注意保护用户的隐私和敏感信息,遵循相关的法律法规。
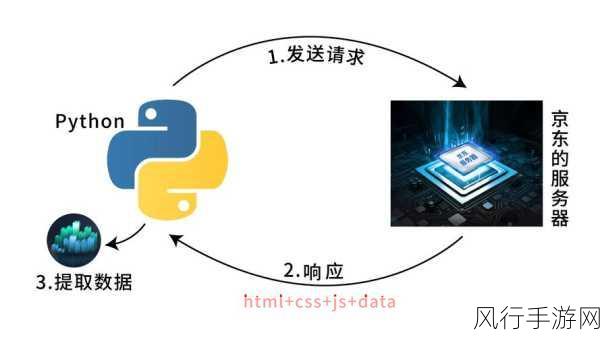
在发送请求时,还应该设置合适的请求头信息,通过模拟真实的浏览器行为,如设置 User-Agent、Referer 等字段,让服务器认为请求来自正常的用户访问,而不是爬虫程序。
使用代理 IP 也是一种常见的方法,当连续使用同一个 IP 地址进行大量请求时,容易被网站识别和封禁,通过使用代理 IP 轮流发送请求,可以降低被封禁的概率。
想要在使用 Python 网络爬虫技术时避免被封禁,需要综合考虑多方面的因素,包括控制爬取频率、尊重网站规则、合理控制数据量、设置正确的请求头以及使用代理 IP 等,只有在合法合规的前提下,充分考虑网站的利益和用户的权益,才能让网络爬虫技术发挥其应有的作用,为我们获取有价值的数据提供有力支持。