探索 Redis 与数据库一致性的维持之道
在当今的数字化时代,数据的一致性对于各类应用系统的稳定运行至关重要,Redis 作为一种高性能的内存数据库,常常与传统的关系型数据库搭配使用,如何确保 Redis 和数据库之间的数据一致性,成为了许多开发者面临的挑战。
要解决 Redis 和数据库一致性的问题,我们需要深入理解它们各自的特点和工作机制,Redis 以其出色的读写性能和丰富的数据结构,常用于缓存热点数据,减轻数据库的负载,但正是因为其数据存储在内存中,可能会出现与数据库数据不一致的情况。
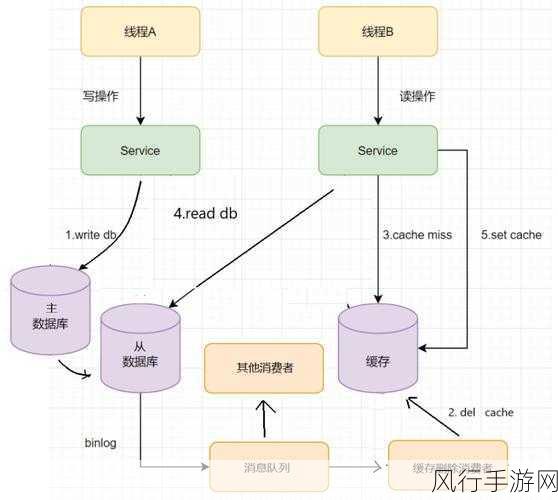
一种常见的策略是采用“先写数据库,再写 Redis”的方式,当有数据更新操作时,首先将新数据写入数据库,确保数据的持久化存储,再将更新后的数据同步到 Redis 中,以保证缓存中的数据也是最新的,但这种方式需要注意处理可能出现的失败情况,比如在写入 Redis 时发生错误。
另一种方法是使用分布式事务来保证一致性,通过引入分布式事务管理器,协调数据库和 Redis 的操作,确保要么两者都成功,要么都失败,不过,分布式事务的实现相对复杂,并且会带来一定的性能开销。

还可以通过消息队列来实现数据的同步,当数据库中的数据发生变化时,发送一条消息到消息队列,然后由专门的处理程序从队列中获取消息,并更新 Redis 中的数据,这种方式能够解耦数据库和 Redis 的直接操作,提高系统的灵活性和可靠性。
定期的数据校验和修复也是必不可少的,可以设置定时任务,对比 Redis 和数据库中的数据,发现不一致时进行修复。
保持 Redis 和数据库的一致性并非一蹴而就,需要根据具体的业务场景和需求,综合运用多种策略和技术,不断优化和完善方案,以确保系统的稳定和数据的准确,在实际应用中,还需要充分考虑系统的性能、可扩展性和容错性,以应对日益复杂的业务需求和不断变化的用户访问模式,只有这样,才能真正实现 Redis 和数据库的完美协同,为用户提供高效、可靠的数据服务。