深入探索 Kafka 数据类型与生产者配置的奥秘
Kafka 作为一种高性能的分布式消息系统,在当今的大数据处理和实时数据传输领域中发挥着重要作用,其数据类型的多样性以及生产者配置的灵活性,为各种应用场景提供了强大的支持。
要理解 Kafka 的数据类型,我们先来看看字节数组(Byte Array),这是 Kafka 中最基本的数据类型,它可以用于存储任意二进制数据,无论是图像、音频,还是自定义的序列化数据,都能以字节数组的形式在 Kafka 中传输。
接下来是字符串(String)类型,字符串在许多应用中都是常见的数据形式,Kafka 对字符串的处理也十分高效,它能确保字符串数据的准确存储和传输,为基于文本的消息传递提供了便利。
然后是整数类型,包括整数(Integer)、长整数(Long)等,这些类型在处理数值数据时非常有用,比如计数、时间戳等。
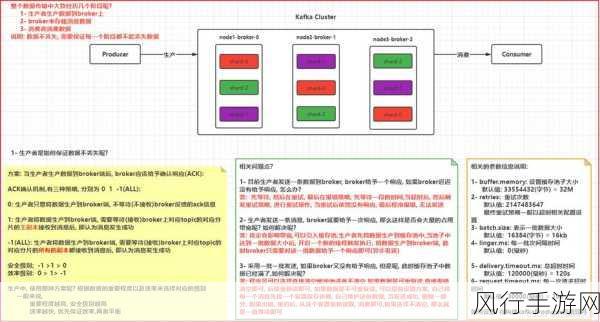
再来说说 Kafka 的生产者配置,分区策略是其中一个关键的配置项,生产者可以根据不同的规则将消息分配到不同的分区,以实现负载均衡和数据分布的优化。
消息的压缩配置也是不可忽视的一部分,通过合理选择压缩算法,如 Gzip、Snappy 等,可以减少网络传输的数据量,提高传输效率,降低存储成本。
acks 配置决定了生产者发送消息后等待服务器确认的方式,不同的 acks 值会影响消息的可靠性和性能之间的平衡。
在实际应用中,根据具体的业务需求和系统环境,精心配置 Kafka 的生产者参数,能够充分发挥 Kafka 的优势,实现高效、可靠的数据传输。
深入了解 Kafka 的数据类型和生产者配置,对于构建高性能、可靠的消息处理系统至关重要,只有掌握了这些核心概念和技术,才能在大数据和实时数据处理的浪潮中,驾驭 Kafka 这一强大的工具,为业务发展提供有力的支持。