探索 Kafka 幂等性在生产者端的精妙实现
Kafka 作为一种强大的分布式消息队列系统,在处理海量数据的消息传递方面表现出色,幂等性是保障数据一致性和准确性的重要特性之一,让我们深入探究一下 Kafka 幂等性在生产者端的实现方式。
要理解 Kafka 幂等性在生产者端的实现,需要先明晰幂等性的概念,幂等性意味着,无论对一个操作执行多少次,其结果都是一致的,在消息传递场景中,这意味着即使生产者发送相同的消息多次,Kafka 也能确保只会持久化存储一次,从而避免数据重复。
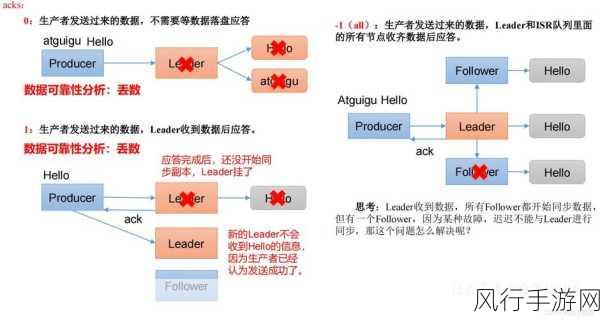
Kafka 为实现生产者端的幂等性,引入了一些关键的机制和技术,最重要的是为每个生产者会话分配一个唯一的 ID,并为每条消息分配一个单调递增的序列号,当生产者发送消息时,这些标识符会随消息一同传递给 Kafka 服务端。
服务端在接收到消息后,会对生产者 ID 和消息序列号进行检查,如果是新的生产者会话,服务端会创建相应的记录并开始处理消息,如果是已存在的生产者会话,服务端会对比接收到的消息序列号与已存储的最大序列号,如果接收到的序列号小于或等于已存储的最大序列号,说明这是重复的消息,直接丢弃;如果接收到的序列号大于已存储的最大序列号,说明这是新的消息,进行正常的处理和存储。
为了确保幂等性的高效实现,Kafka 还在内部进行了一系列的优化,对生产者 ID 和序列号的存储和检索进行了精心设计,以提高性能和减少资源消耗,Kafka 还通过巧妙的缓存机制,减少了不必要的重复计算和数据传输。
生产者端在发送消息时,也需要遵循一定的规则和最佳实践,要确保在同一个生产者会话中发送的消息具有正确的序列号递增顺序,避免出现乱序的情况,要合理处理网络异常和错误,确保在重试发送消息时不会导致重复发送。
Kafka 幂等性在生产者端的实现是一个复杂而精妙的过程,它充分考虑了各种可能的情况和异常,通过巧妙的设计和优化,为用户提供了可靠的数据一致性保障,在实际应用中,合理利用 Kafka 的幂等性特性,可以大大简化业务逻辑的处理,提高系统的稳定性和可靠性。