探索 Python 数据存储在大数据环境下的独特魅力
在当今数字化时代,数据已成为企业和组织的核心资产,随着大数据技术的迅猛发展,如何有效地存储和管理海量数据成为了关键问题,Python 作为一种广泛应用的编程语言,在大数据处理领域也发挥着重要作用。
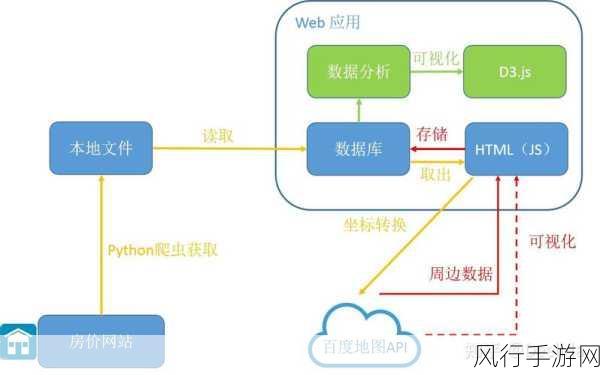
Python 具有丰富的库和工具,为数据存储提供了多种选择,Pandas 库是 Python 中用于数据处理和分析的强大工具,它支持多种数据格式的读取和写入,包括 CSV、Excel、SQL 数据库等,通过 Pandas,我们可以轻松地将数据加载到内存中进行处理和分析,并将处理后的结果保存为所需的格式。
Python 中的 NumPy 库提供了高效的数组操作功能,适用于处理大规模的数值数据,在大数据环境下,NumPy 可以与分布式计算框架如 Dask 结合使用,实现对大规模数据的并行处理和存储。
对于结构化数据的存储,Python 可以与关系型数据库(如 MySQL、PostgreSQL 等)进行交互,通过使用相应的数据库驱动程序和库(如 SQLAlchemy),我们可以在 Python 中执行数据库操作,如创建表、插入数据、查询数据等。
而在处理非结构化数据(如文本、图像、音频等)时,Python 中的一些库如 PyTorch、TensorFlow 等可以用于构建深度学习模型,对非结构化数据进行特征提取和处理,并将处理结果进行存储。
在大数据环境中,数据的存储不仅仅是将数据保存起来,还需要考虑数据的一致性、完整性、可用性和可扩展性,Python 可以与分布式文件系统(如 HDFS)和分布式数据库(如 MongoDB、Cassandra 等)集成,实现数据的分布式存储和管理。
Python 还可以用于构建数据仓库和数据湖,数据仓库通常用于存储经过清洗、转换和聚合的结构化数据,以便进行快速的查询和分析,而数据湖则可以存储各种类型的数据,包括结构化、半结构化和非结构化数据,为数据的探索和创新应用提供了更大的灵活性。
Python 在大数据环境下的数据存储中展现出了强大的能力和灵活性,通过合理地选择和运用相关的库和工具,结合大数据技术的架构和理念,我们能够有效地存储和管理海量数据,为数据驱动的决策和创新提供有力支持,随着技术的不断发展和创新,相信 Python 在大数据领域的应用将会越来越广泛,为我们带来更多的惊喜和价值。