探索 Cassandra 数据一致性部署的难易之谜
Cassandra 作为一种流行的分布式数据库,其数据一致性部署问题一直备受关注,Cassandra 数据一致性部署到底复杂与否呢?
要回答这个问题,我们需要先了解 Cassandra 的一些基本特性,Cassandra 是为了处理大规模数据和高并发读写而设计的,它采用了分布式架构,数据分布在多个节点上,这种分布式的特点在带来优势的同时,也给数据一致性的实现带来了挑战。

Cassandra 提供了多种一致性级别可供选择,从强一致性到最终一致性,不同的一致性级别在性能和数据一致性之间做出了不同的权衡,强一致性能够确保数据在任何时候都是一致的,但可能会对系统的性能产生一定的影响;而最终一致性则更注重系统的性能和可扩展性,但在数据一致性的保障上相对较弱。
在实际部署中,网络延迟、节点故障等因素都会对数据一致性产生影响,为了确保一致性,需要精心设计系统的架构和配置,这包括合理规划节点的分布、设置副本数量、优化网络拓扑等,还需要考虑数据的读写模式,根据具体的业务需求选择合适的一致性级别。
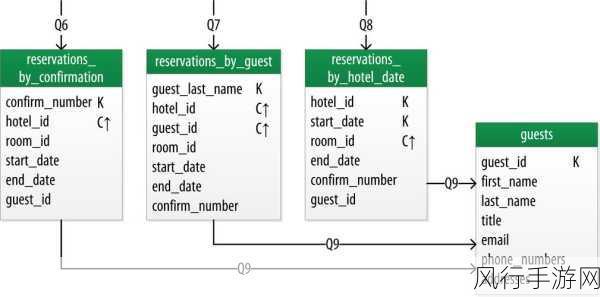
Cassandra 的数据一致性机制并非一劳永逸,需要不断地进行监控和调整,随着业务的发展和数据量的增长,原先的部署方案可能不再适用,需要及时进行优化和改进。
Cassandra 数据一致性部署具有一定的复杂性,它需要综合考虑多种因素,包括系统架构、业务需求、性能要求等,但只要对 Cassandra 的原理和机制有深入的理解,并且具备丰富的分布式系统部署经验,就能够有效地应对这些挑战,实现满足业务需求的数据一致性。
对于那些打算采用 Cassandra 并关注数据一致性的开发者和团队来说,充分的前期调研和测试是至关重要的,只有这样,才能在实际部署中少走弯路,确保系统的稳定和可靠。