探秘 Python 爬虫框架的核心魅力
在当今数字化信息时代,数据的价值日益凸显,而 Python 爬虫框架成为了获取数据的重要工具,掌握 Python 爬虫框架的精髓,不仅能够帮助我们高效地获取所需信息,还能为数据分析、机器学习等领域提供有力支持。
要深入理解 Python 爬虫框架,我们需要从多个方面入手,其一,必须熟悉网络请求的基本原理,这包括了解 HTTP 协议、请求方法(如 GET、POST 等)以及响应状态码的含义,只有对这些基础知识有清晰的认识,我们才能在编写爬虫代码时准确地发送请求并处理响应。
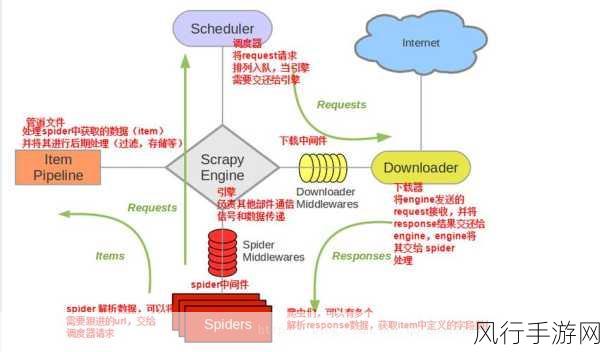
掌握数据解析技术也是关键所在,无论是 HTML、XML 还是 JSON 格式的数据,我们都要能够熟练地运用相应的解析库进行提取和处理,BeautifulSoup 库用于解析 HTML 文档,而 json 模块则用于处理 JSON 数据。
反爬虫机制的应对策略也不可忽视,许多网站为了防止被过度爬取,设置了各种反爬虫措施,如 IP 封禁、验证码、请求频率限制等,我们需要学会使用代理 IP、设置合理的请求间隔,甚至模拟人类行为来绕过这些限制。
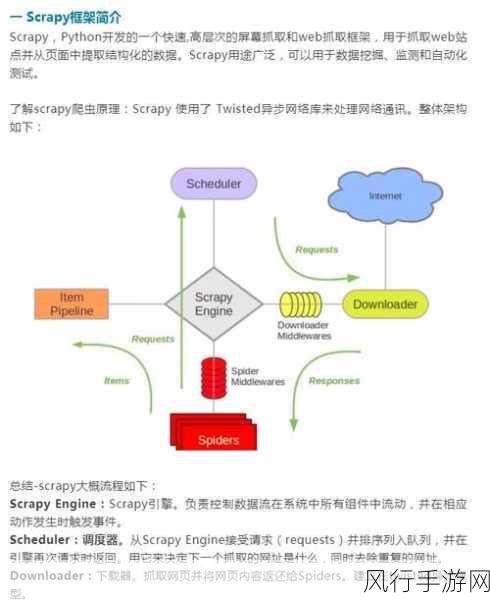
还需注重代码的优化和可维护性,良好的代码结构、注释和错误处理机制能够让我们的爬虫程序更加稳定可靠,并且便于后续的修改和扩展。
掌握 Python 爬虫框架的精髓并非一蹴而就,需要我们不断学习和实践,通过积累网络知识、提升数据处理能力、应对反爬虫挑战以及优化代码,我们能够打造出高效、稳定且合法的爬虫程序,为我们的数据分析和应用开发提供丰富的数据资源,但需要特别强调的是,在使用爬虫技术时,务必遵守法律法规和网站的使用规则,尊重他人的权益,以确保我们的行为是合法且道德的。