探索 Seatunnel 与 Kafka 数据同步的精妙之旅
在当今数字化时代,数据的流动和同步成为了企业和组织发展的关键环节,Seatunnel 和 Kafka 作为强大的数据处理工具,它们之间的数据同步实现方式备受关注。
Kafka 作为一款分布式的消息队列系统,具有高吞吐量、低延迟和可扩展性等优势,而 Seatunnel 则是一个高效的数据集成工具,能够在不同数据源之间实现数据的迁移和同步。
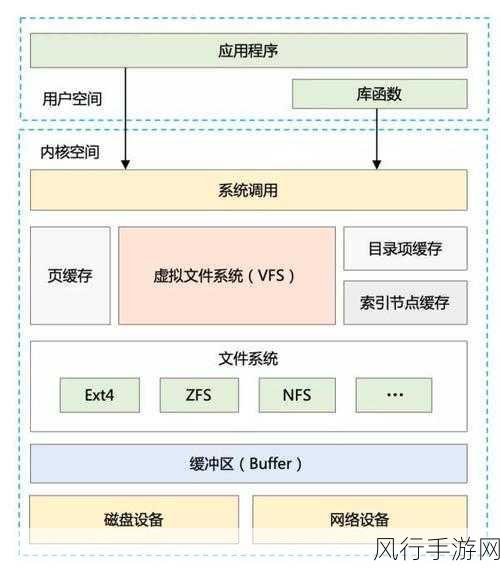
要实现 Seatunnel 与 Kafka 的数据同步,需要对两者的特性和工作原理有深入的理解,我们需要明确数据的来源和目标,如果数据来源于关系型数据库,那么需要通过适当的连接器将数据抽取出来。
在配置 Seatunnel 时,需要准确设置相关的参数,以确保与 Kafka 的连接和数据传输的稳定性,这包括 Kafka 的主题名称、分区信息、数据格式等,还需要考虑数据的转换和处理逻辑,以满足业务需求。
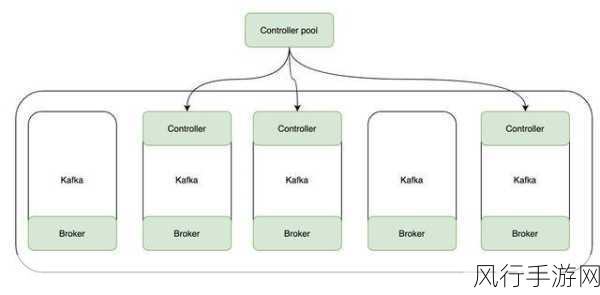
数据同步的过程中还需要关注数据的一致性和完整性,可能会遇到数据丢失、重复等问题,这就需要通过一些机制来进行保障,比如数据的校验、错误处理和重试策略。
为了优化数据同步的性能,还可以采用一些技巧,比如合理调整并行度、优化数据存储和传输方式等。
实现 Seatunnel 与 Kafka 的数据同步并非一蹴而就,需要综合考虑多个因素,进行精细的配置和优化,以确保数据能够准确、高效地在两者之间流动,为企业的业务发展提供有力支持,通过不断的实践和探索,我们能够更好地掌握这一技术,为数据处理和应用带来更多的价值。